Project Showcase
The collection.
Deep Learning NSFW Image Classifier
Deep Learning | Computer Vision
SMS Spam Detection Classifier
NLP | Machine Learning | Text Classification
IMDB Movie Review Sentiment Classifier
NLP | Deep Learning | Sentiment Analysis | Text Classification
Reddit Post Authorship & Behavioral Analysis
NLP | Reddit API | Data Visualization | Text Classification
Salmon Weight Prediction with Support Vector Regression
Machine Learning | Regression | Data Cleaning
Deep Learning NSFW Image Classifier
Project Type: Image classification using TensorFlow and deep learning
Type: Deep Learning | Computer Vision
Tools: Python | TensorFlow | Keras | OpenCV | NumPy | Reddit API | Jupyter | GitHub
Overview:
Developed a deep learning model to detect and classify unsolicited explicit images (commonly known as “dick pics”) to promote safer digital environments. The model distinguishes between explicit and non-explicit content with 99.26% accuracy using a custom-built image dataset.
Key Technologies:
- Languages & Frameworks: Python, TensorFlow, Keras, Scikit-learn
- Libraries & Tools: OpenCV (image processing), Pandas, NumPy, Matplotlib, PRAW (Reddit API), Jupyter Notebook, VS Code
- OS & Virtualization: Windows 10/11, Linux Mint (via VMware), Anaconda Navigator
- Version Control: GitHub
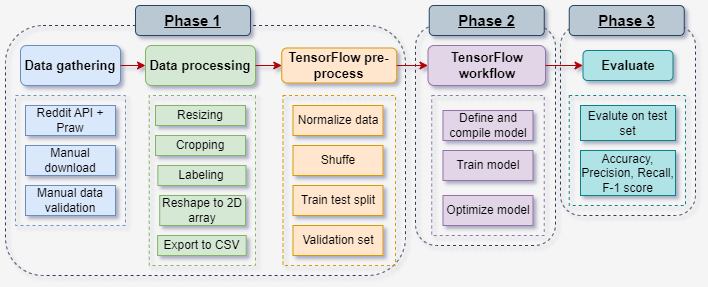
Process Highlights:
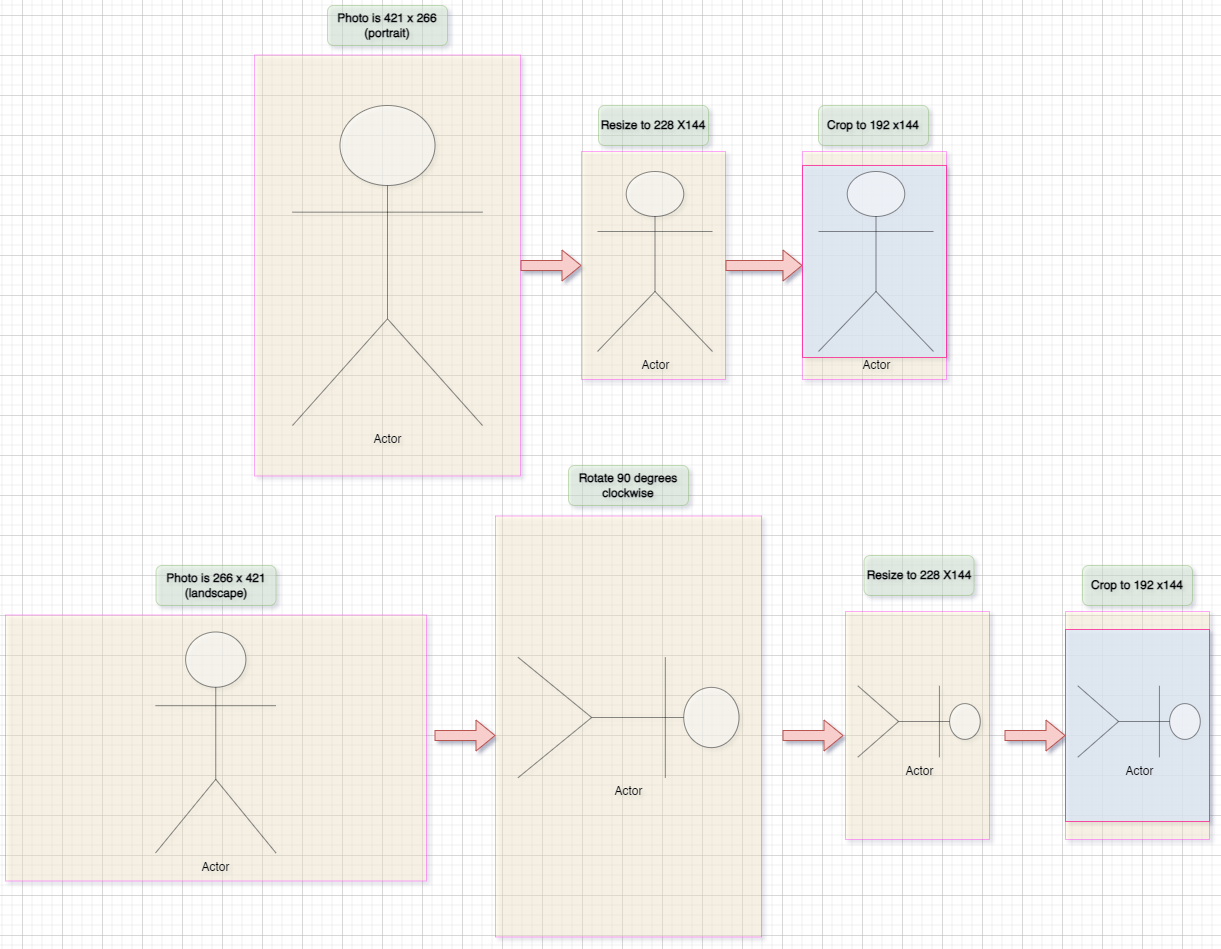
- Data Collection & Preprocessing:
- Manually gathered and web-scraped over 250K unique images
- Removed duplicates, resized images, maintained aspect ratios, labeled data
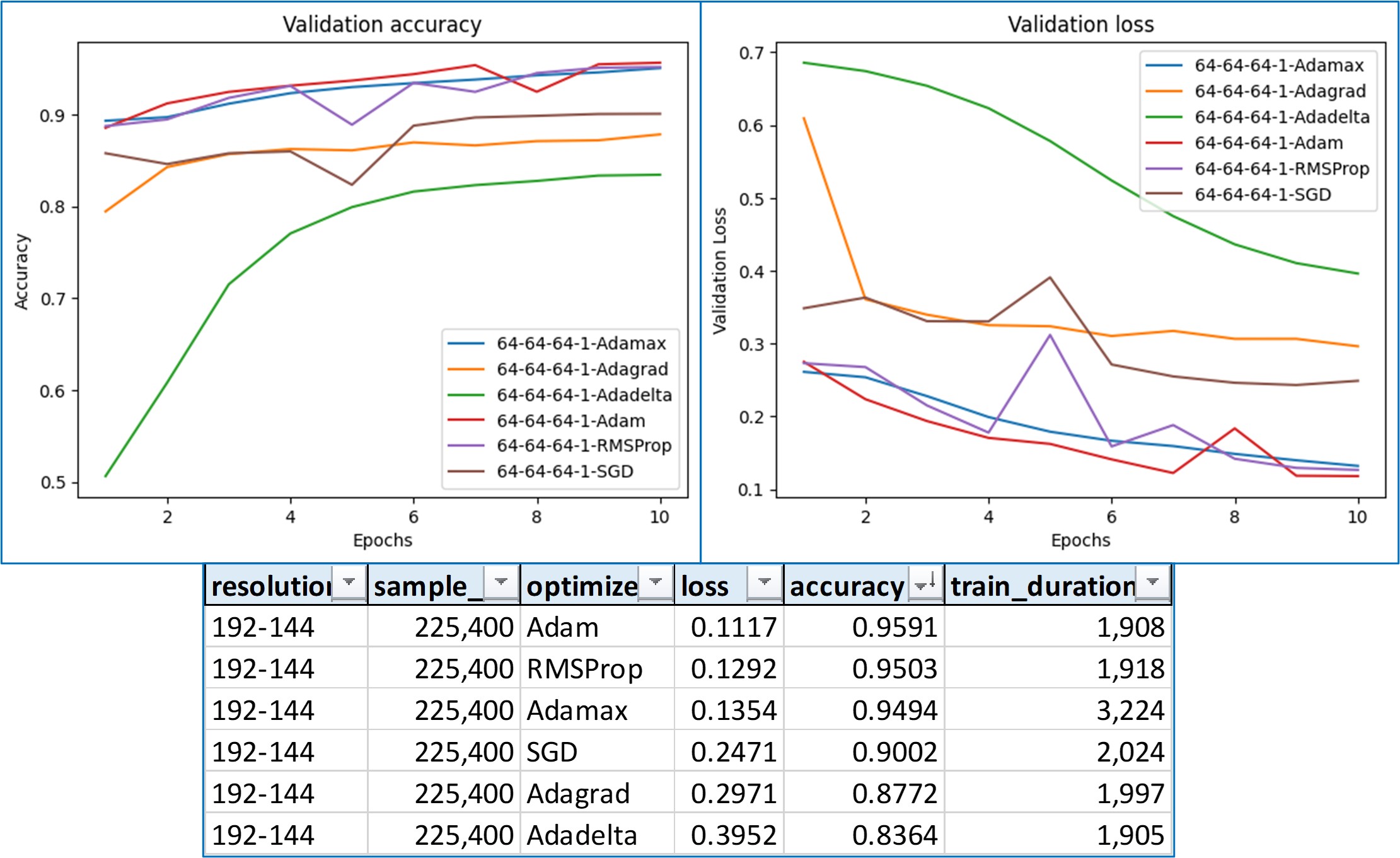
- Model Architecture:
- 5 Conv2D layers → Flatten → 6 Dense layers
- Final output layer uses sigmoid for binary classification
- Trained using binary cross-entropy loss, Adam optimizer
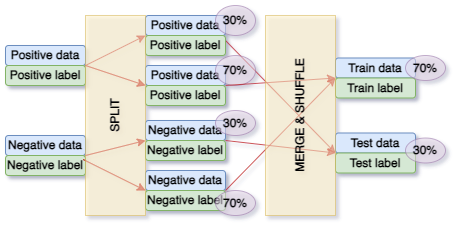
- Training & Evaluation:
- Dataset split: 50% training, 25% validation, 25% testing
- Batch size: 128, Epochs: 35
- Achieved 99.26% accuracy and 0.0213 loss on test set (56K+ samples)
Impact:
Successfully built a high-accuracy model capable of flagging explicit content, which could be integrated into social media platforms or messaging apps to improve user safety and content moderation.

SMS Spam Detection Classifier
Project Type: Image classification using TensorFlow and deep learning
Type: NLP | Machine Learning | Text Classification
Tools: Python | Scikit-learn | TF-IDF | Naive Bayes | Logistic Regression
GitHub: https://github.com/birdmoney11/portfolio-samples/tree/main/NLP%20SMS
Overview:
Developed a natural language processing (NLP) pipeline to automatically classify SMS messages as spam or ham (not spam) using classic machine learning models and vectorization techniques. Achieved a 97% test accuracy using a Naive Bayes classifier, and cross-verified with a Logistic Regression model.
Problem & Motivation
With SMS marketing growing at over 20% CAGR worldwide, filtering spam is increasingly critical. This project aims to implement a scalable spam detection system based on publicly available SMS datasets and common NLP techniques.
Dataset
- Source: UCI SMS Spam Collection
- Samples: 5,574 SMS messages (747 spam / 4,827 ham)
- Languages: English (UK & Singapore regional differences noted)
- Challenge: Linguistic and vocabulary variation created natural biases in the dataset, which were mitigated through preprocessing and normalization.
Tools & Technologies
- Languages: Python
- Libraries: Scikit-learn, NLTK, Pandas, NumPy, Seaborn, Matplotlib
- Models: Multinomial Naive Bayes, Logistic Regression
- Vectorization: Bag of Words, TF-IDF, 1–3 gram range
- Preprocessing: HTML unescape, punctuation/stopword removal, lemmatization (WordNet)
- Evaluation: Confusion Matrix, Classification Report, Heatmaps
Implementation Workflow
- Data Cleaning: HTML decoding, noise removal, lowercasing
- Tokenization & Lemmatization: Preprocessed into root words for better semantic matching
- Feature Extraction:
- CountVectorizer (BoW)
- TF-IDF with unigrams, bigrams, and trigrams (max 2,500 features)
- Model Training & Testing:
- Stratified 75/25 train-test split
- Applied both Naive Bayes and Logistic Regression for comparative analysis
Results
Naive Bayes Classifier:
- Test Accuracy: 97%
- Spam Precision: 0.77
- Spam Recall: 0.98
- F1-Score: 0.86
Logistic Regression:
- Test Accuracy: 96%
- Slightly lower spam precision than Naive Bayes
Both models performed well, but Naive Bayes showed higher robustness in detecting spam with fewer false negatives—critical for spam detection applications.
IMDB Movie Review Sentiment Classifier
Project Type: Sentiment analysis using TensorFlow and deep learning
Type: NLP | Deep Learning | Sentiment Analysis | Text Classification
Tools: Python | TensorFlow | Keras
GitHub: https://github.com/birdmoney11/portfolio-samples/tree/main/ML%20IMDB
Overview:
A binary classification project using deep learning to determine sentiment polarity (positive or negative) of movie reviews from the IMDB dataset.
Problem & Dataset
- Task: Classify movie reviews as either positive (≥7/10) or negative (≤4/10) to avoid ambiguity from neutral scores.
- Dataset: IMDB dataset from keras.datasets, with 50,000 pre-tokenized reviews, split evenly into training and test sets. Each review is encoded using a Bag-of-Words (BoW) technique.
Model Architecture
- Built with Keras Sequential API, the model comprises:
- Embedding layer for word vector representation
- GlobalAveragePooling1D to flatten embeddings
- Dense layers with ReLU activation
- Sigmoid output for binary classification
Tools & Technologies
- Languages: Python
- Libraries: TensorFlow, Keras, NumPy, Pandas, Matplotlib, Seaborn
- IDE: Jupyter Notebook, VS Code
- Evaluation Tools: Confusion Matrix, Classification Report (precision, recall, f1-score)
Evaluation & Results
- Accuracy: 87.52%
- Loss: 0.3723
- Metrics:
- Positive review recall: 0.90
- Negative review precision: 0.89
- Balanced F1-scores (~0.88) indicate strong performance for both classes
Key Features & Highlights
- Applied Hold-Out Validation to split data into training and validation subsets.
- Used classification metrics and visualization (confusion matrix, precision-recall plots) for in-depth model evaluation.
- Demonstrated ability to preprocess data, build text pipelines, and tune neural networks.
Reddit Post Authorship & Behavioral Analysis
Project Type: NLP and Data Visualization
Type: NLP | Reddit API | Data Visualization | Text Classification
Tools: Python | Pandas | Matplotlib | Seaborn
GitHub: https://github.com/birdmoney11/portfolio-samples/tree/main/DS%20Reddit%20post
Project Objective
Analyzed the writing style, vocabulary, and activity patterns of two Reddit users—Shittymorph (SM) and GuyWithFacts (GWF)—to evaluate the hypothesis: Are these accounts operated by the same person?
This project combines natural language processing (NLP), behavioral analysis, and custom visualization to explore authorship attribution in real-world online forums.
Tools & Technologies
- Languages & Libraries: Python, Pandas, NumPy, Seaborn, Matplotlib
- APIs: PRAW (Python Reddit API Wrapper)
- NLP Techniques: Tokenization, stopword removal, custom regex filtering
- IDE: Jupyter Notebook
Data Collection & Preprocessing
- Fetched Reddit comments using PRAW for both SM and GWF accounts
- Removed repeated quotes and “copypasta” (e.g., Undertaker meme lines) using regex and str.replace()
- Applied lowercasing, punctuation removal, and stopword filtering
- Created separate labeled datasets for side-by-side analysis
Feature Engineering & Analysis
- Word Cloud Visualizations: Captured vocabulary richness and dominant word themes
- Comment Length Histograms: Showed SM preferred short posts (peaking at 50–100 words), while GWF leaned toward long-form replies (100–300+ words)
- Hourly Activity Heatmaps: Compared time-of-day posting patterns across users
- Lexical Analysis: Identified differences in tone, sentiment, and topic focus
Key Results
- Distinct Posting Behavior: SM used more informal, meme-driven language; GWF’s posts were longer and more introspective
- Unique Vocabularies: Clear divergence in top-used words—no major overlap
- Time-of-Day Activity: Posting hours differed, reinforcing behavioral distinctions
Conclusion
The evidence strongly suggests SM and GWF are separate individuals. This analysis successfully applied NLP, real-world API data scraping, and visual storytelling to approach a forensic linguistics-style question.
Skills Demonstrated
- Natural Language Processing (NLP)
- Data Wrangling & Cleaning
- API Integration (PRAW)
- Custom Text Preprocessing with Regex
- Data Visualization & Exploratory Analysis
- Behavioral Pattern Recognition
Salmon Weight Prediction with Support Vector Regression
Project Type: Sentiment analysis using TensorFlow and deep learning
Type: Machine Learning | Regression | Data Cleaning
Tools: Python | Scikit-learn | NumPy | Pandas | Matplotlib | Seaborn
GitHub: https://github.com/birdmoney11/portfolio-samples/tree/main/DS%20Salmon%20size
Project Overview
This project builds a regression-based machine learning model to predict the weight of Pacific salmon based solely on their length, enabling potential real-time applications in ecological monitoring and AI-powered species recognition systems.
Dataset
- Source: Alaska Salmon Survey data (via Kaggle)
- Size: ~14 million records (filtered to ~677,000 valid samples)
- Species: Chinook, Chum, Coho, Pink, Sockeye
- Key Features: Length (input), Weight (target variable)
- Use Case: Simulates AI applications in wildlife management like Norway’s invasive species detection system
Methodology
- Data Cleaning
- Removed nulls, duplicates, and inconsistent records
- Focused on biologically valid combinations (e.g., Chinook species with realistic weight-length pairs)
- Exploratory Data Analysis
- Found correlations between age, gender, and weight
- Verified statistical distributions across species
- Modeling: Support Vector Regression (SVR)
- R² Score
- Mean Absolute Error (MAE)
- Root Mean Square Error (RMSE)
- Used scikit-learn's SVR() with RBF kernel
- Input: Salmon length
- Target: Weight
- Train/test split: 80/20
- Performance evaluated using:
- Visualization
- Created 2x2 subplots showing prediction vs. actual values
- Compared multiple models (SVR #1 vs SVR #2) for robustness across different data subsets
Results & Insights
- SVR predicted weight values that closely followed the actual regression curve
- Model #2 performed better at higher-length values
- Key Insight: With high-quality, cleaned data, simple ML models like SVR can yield highly accurate predictions
- Limitation: Highly processed data may inflate apparent accuracy—future work could explore raw data performance
Real-World Relevance
- Enables non-invasive, real-time predictions of fish weight using only visual input
- Could power camera-based AI systems to assist in species detection, invasive species filtering, or population studies
- Highlights use of ML in marine biology, sustainability, and automation
Tools & Technologies
- Python, NumPy, Pandas, Matplotlib, Seaborn
- Scikit-learn (SVR, model selection, metrics)
- Jupyter Notebook, Visual Studio Code